Run Azure Batch From Azure Data Factory V2
Azure Data Factory v2 allows for easy integration with Azure Batch. Azure Batch brings you an easy and cheap way to execute some code, such as applying a machine learning model to the data going through your pipeline, while costing nothing when the pipeline is not running.
What I’m going to illustrate below is the following:
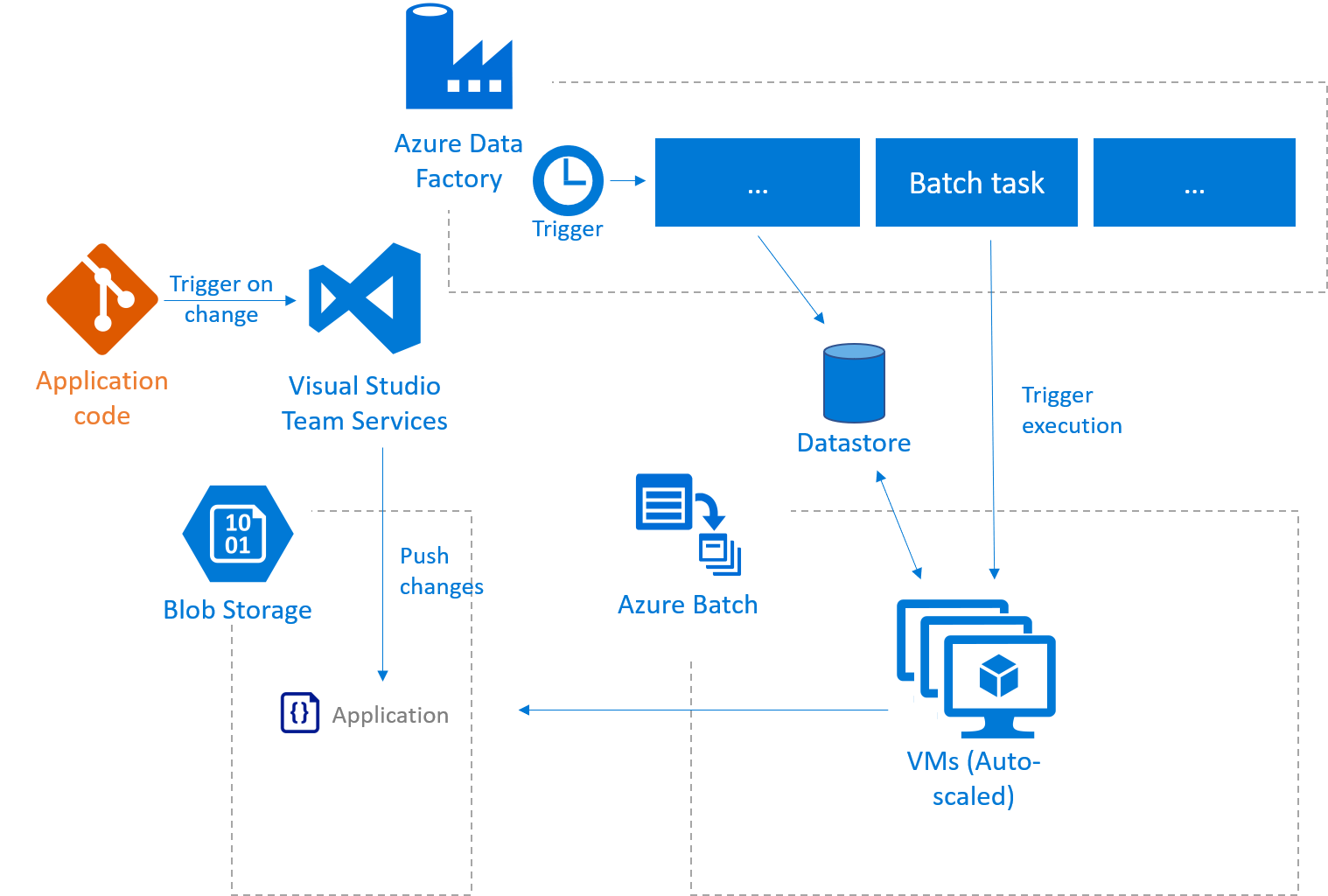
- A data factory pipeline gets triggered on a schedule
- The pipeline does some transformation, stores everything into a staging datastore
- The application we want to run on Azure Batch sits in a Blob store and gets updated by VSTS
- Data factory triggers the batch job, and references the application
- Azure Batch scales up and processes the tasks
- Data factory carries on.
Preparing the Azure Batch execution environment
Create an Azure Batch resource. Within that resource, create a pool. Configure that pool to autoscale. Here is an example of autoscale calculation that will scale down to 0, check every 5 minutes if there’s work, scale up if so, then back down if necessary. You can tune it to ask for low priority VMs, or a mix of so.
maxNumberofVMs = 10;
samplingInterval = 5 * TimeInterval_Minute;
averageProcessingTimeSeconds = 5;
targetProcessingTimeSeconds = 60;
minimumDesiredSampleDataPercent = 70;
pendingTaskSamplePercent = $PendingTasks.GetSamplePercent(samplingInterval);
pendingTasksCount = (pendingTaskSamplePercent < 70) ? 0 : avg($PendingTasks.GetSample(samplingInterval));
estimatedProcessingTimeSeconds = pendingTasksCount * averageProcessingTimeSeconds;
processorTarget = pendingTasksCount > 0 ? max(estimatedProcessingTimeSeconds / targetProcessingTimeSeconds, 1) : 0;
$TargetDedicatedNodes = min(maxNumberofVMs, processorTarget);
$NodeDeallocationOption = taskcompletion;
You also need to setup the start-up tasks of the node pool so that it installs any requires software. For example, if you need to install Python 3 on a Linux cluster, then your start task will look like so:
/bin/bash -c "
sudo apt-get update
sudo apt-get install -y python3 python3-pip"
Note that you need to specify the full path to the application you need to run. As such, it’s easier to run your script as a bash inline command so you get the environment variables (inc. $PATH) set.
Preparing the application
In this example, the application sits in a blob storage container. This means that the deployment consists in copying the file to blob storage. To do so, create a storage account, and a container within it. Then create a release pipeline with an AzureBlob File Copy task targeting this container:

Execute the pipeline then make sure the application is there:

You could also package your application within a container
Application deployment considerations
Batch provides you with a white VM and a small framework running on top of it, which means there are plenty of ways to deploy your application:
- Create an Azure Batch application package: Azure Batch integrates its own application package framework, which includes some form of version control. This is powerful, but comes at the cost of addition efforts to deploy an application. This option is very allows you yo use several versions of the application in parallel (e.g. customer 1 uses version 1.2 of your prediction model, whereas customer 2 uses version 1.3). You can still replicate that very easily with just various directories in blob storage. Overall, I would consider this option if the time it takes to setup the application is significant compared to the total execution time of the application in a single batch. That is: you have 1000 tasks from Data Factory, each task takes ~1s, and setting up the application takes >1s, then you’ll be better off having the application setup once per machine only. If you decide to go with that option, then having the application package deployed will require for the machines to be cycled. Additionally, you’ll have to write some CLI script within your VSTS deployment to handle application package creation.
- Use blob storage per task: this is the simplest option, which guarantees you have the latest version of the application with each execution of a script. However, this also means that the application will get installed for each task run. This may be good if the tasks depend on different versions. This is not a significant problem if copying the application and setting it up is marginal. Else, consider another option.
- Use a container: package your application as a container and
deploy it as a start task. This is particularly useful in a few
cases:
- if the environment setup is time consuming1, in which case containers will help having everything prepared in advance ;
- containers also package things in a nice package, so if you need to run the application as it was deployed on a certain date, that may be useful ;
- when you get discrepancies when executing between your dev environment and the production environment, in which case containers will help making sure you have the same setup in both. Overall the complexity associated with that is fairly low, but still higher than just having blob storage.
- Use a pre-cooked image: the image you’re using for Azure Batch can be your own. This is by far the fastest deployment method, since you get the VM started with the environment right away, but also the most complex to maintain.
When deciding, keep in mind that speed might not be that relevant. If you’re running a daily batch, it may not matter. You have a large scale, and the minutes spent booting up the machine add up to a cost larger than that of the time you spend optimizing bootup time, then it may matter. If data is streamed, the response time is important, and the scale varies, then optimizing bootup may be important as well.
Create the data factory pipeline
Create a data factory v2. Then configure connections:
- To the blob storage account containing your application
- To the batch pool that you created earlier.

Create a pipeline and bring in a batch task. Configure it to use the connection you built, then put a command that’s gonna be executed, such as2:
/bin/sh -c 'python3 launch.py "@pipeline().RunId"'
Then bring up the resource link for the storage account you configured, and indicate the container name for the application to deploy on the node.
During execution of the task, the batch framework will download the app into the local folder.
Then publish your changes with the publish all button, and click “Trigger” to trigger the pipeline.
Observe the batch running
You can use Batchlabs to monitor your batches.
Notes
-
libraries to install them.
-
and pass it to the application you run